TL;DR
在資料分析的領域中,資料品質有點像是「溫室效應」: 大家都知道它很重要,卻不是每個人都想花時間處理,然後有一天,就 Fucked Up 了。
近期試著在部門建立監控資料品質的機制,透過這篇文章記錄過程中建立的知識點,以及最後是怎麼實作出監控模組,可套用在既有的數百個 ETL。
到底哪裡出了問題?
大約半年前,我正在前一份工作建模,在確定了基本的模型架構後,使用手邊現有的資料進行預測,結果相當不錯! 團隊歡欣鼓舞。
到了下個月,新的資料收集完畢,丟進一樣的模型做預測,結果慘不忍睹,團隊成員面面相覷。
欸! 你有改模型的架構嗎?
沒…沒有阿…?
會不會這個月的資料本來就怪怪的啊…?
我…我也不知道欸…

模型的架構,可以透過程式碼版控去追蹤每個版本的更動。
而每一批資料的變動是否有異常的情況發生,這就需要花點工夫深入了解了。
對建模的迷思
剛踏入資料分析的領域時,有種迷思:
如果預測結果不好,一定是這個模型架構太爛了!
所以花了很多時間去追最新的模型架構、研讀新的論文,陷入了一種「套件工程師」的感覺: 把相同的資料,丟進不同的模型試試,如果表現不好,就再換一種模型。
直到上了 Andrew Ng. 的 Coursera 課程 - MLOps Specialization
其中分享了一個觀念: Model-Centric 與 Data-Centric AI 的不同,分別是透過改善模型及改善資料兩種截然不同的策略,來達到優化預測結果的目的。
在 Andrew 公司內部的多個專案中,他們發現改善資料的優化幅度是遠大於改善模型的。而要做到改善資料,前提當然是要深入的瞭解資料。
如果有興趣的讀者,也可以前往課程觀看相關內容:
資料品質
不同面向、難有統一標準
如果要對資料品質進行較明確的定義,我會這麼形容:
透過指標來評估資料的狀況是否正確及可靠
實際上資料品質涵蓋了許多不同的面向:
- 完整度
- 一致性
- 使用性
- 可靠性
- 時效性
這些面向中,很難找到一組標準是「放諸四海皆準」,適用於所有的情況。基本上這些指標是因應各個分析團隊的需求而異。
舉個例子來說: 一批資料缺少了生日欄位,對某些團隊來說,這樣是「無法接受」的,因為少了可以運用的 Feature。
但或許對於銀行的分析團隊來說,這樣才是「合法」的,因為金融法規有規定做分析前需要進行「去識別化」。
資料品質標準化
許多公司其實都有推行自己的資料品質監控平台:
AWS:
Amazon建立了
Deequ這個工具,用來進行資料品質的計算,並且據此建構了內部的資料品質計算工具。Test data quality at scale with Deequ
Uber:
Uber 則在部落格分享內部的
UDQ(Uber Data Quality Platform)是如何運作的。How Uber Achieves Operational Excellence in the Data Quality Experience
其中 Uber 在文章中分享到建立平台前,他們向內部的 Data Consumer 和 Data Producer 分別收集了相關需求,在五花八門的需求中,梳理出幾個類別,這可以協助我們了解常見的資料品質指標:
| 類別 | 定義 |
|---|---|
| Completeness | 資料完整度,從上游任務轉到下游任務時,資料的完整程度 |
| Freshness | 資料轉移過程中,達到99.9%完整度所需的時間 |
| Duplicates | 一批資料中,主鍵是唯一的比例 |
| Cross-Datacenter Consistency | 該批資料與其他資料中心的一致程度 |
| Others | 使用者自行定義,無其他標準 |
建立資料品質監控模組
在規劃及設計這個專案時,考量了幾個重點:
需與現有的ETL流程有極高的相容性:
部門現有的ETL流程主要透過
Airflow進行驅動,我所設計的模組必須要相容於Airflow的流程。如果為了達到資料品質監控目的,而開發了額外的服務,可能會因為相容成本過高,難以推行。能計算基本的資料品質:
現有的 ETL 流程約有 400 個,如果每一個流程都需要客製化地設計檢驗項目,需要花費太多人力成本。因此模組需要具備「計算基本指標」的功能,對於任何資料都先做初步的檢驗。
使用者可根據需求自訂規則:
如同前一節所提到,資料品質的指標因團隊而異,除了基本指標外,需要提供接口讓使用者可自行設定客製化的條件。
接下來,就讓我們從基本的 ETL 流程出發,進行一趟資料品質的旅程:

Metric Operator
首先,我們先在架構圖中,加入了第一個元件 Metric Operator:
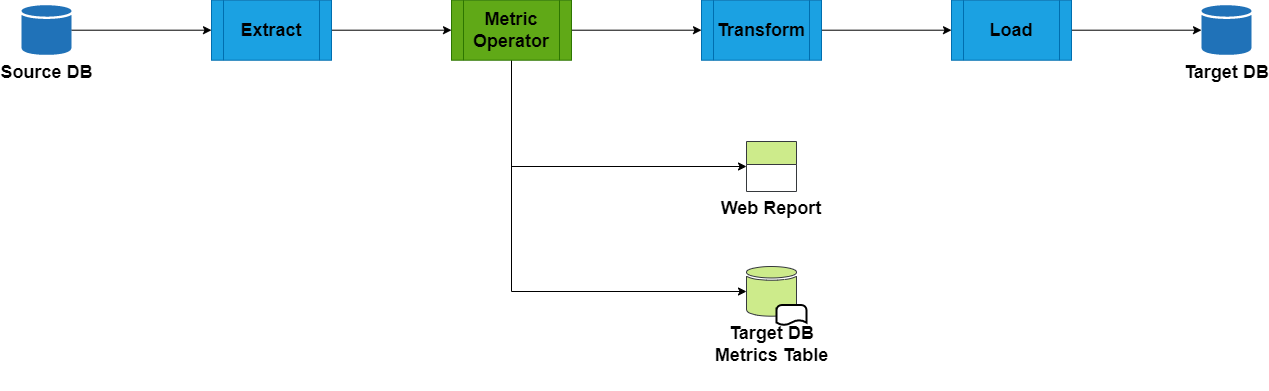
對資料進行初步探索、了解基本樣貌
從架構圖中可以看到 Metric Operator 會在 ETL 的過程中,將 Raw Data 分流出來進行基本運算,得到兩個產物: Web Report 及 Metric Table。
Web Report:
Web Report是理解資料的入口,使用者在設計更複雜的規則前,透過視覺化的報表,可以了解各變數的分布、取得基本的視覺化、得到各項欄位的基礎提示(例如該欄位值皆為空、此欄位分布不均勻…)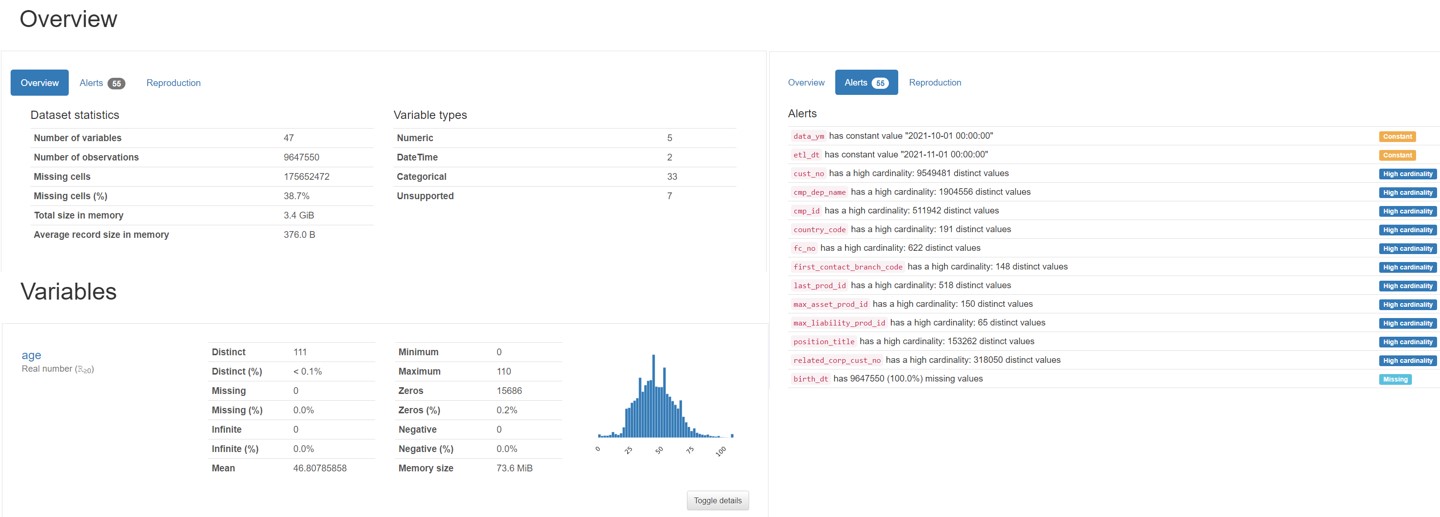
Metric Table:
第二項產物是結構化的
Metric Table,Metric Operator滾算各欄位的基本統計量,包含下面幾項:欄位 意義 n 數量 n_missing 空值數量 p_missing 空值百分比 n_unique unique 數量 p_unique unique 百分比 n_distinct distinct 數量 p_distinct distinct 百分比 計算出各欄位的基本統計量後,將其轉為結構化報表存放至RDB中。
API Server
接著我們在架構圖中加入API元件:

使用者透過 FastAPI 所建立的 API Server 來設定資料品質的檢驗條件。
(PS: 對於 FastAPI 不熟悉的讀者,歡迎造訪: FastAPI入門筆記(一) - 基本介紹)
舉例來說:
{
"user_name": "MingLun",
"checker_name": "first_checker",
"rules":[
{
"stat_column": "person_id",
"stat_name": "n_distinct",
"operator": ">",
"threshold":100
}
]
}
從上述的設定中,我們設定了一個屬於 MingLun 的檢驗物件,檢驗的條件是person_id這個欄位必須要有100個以上的distinct值。
(我們可能希望這批資料至少要有超過100個人,不能都是同樣的person_id)
API Server 讓使用者(有資料品質檢驗需求的人)可以自由的CRUD檢驗物件,這些物件會在下一節中被使用到。
Rule / Validate Operator
接著我們在原先的架構圖上再加入Rule Operator 及 Validate Operator 兩個元件,現在的架構圖會變成:
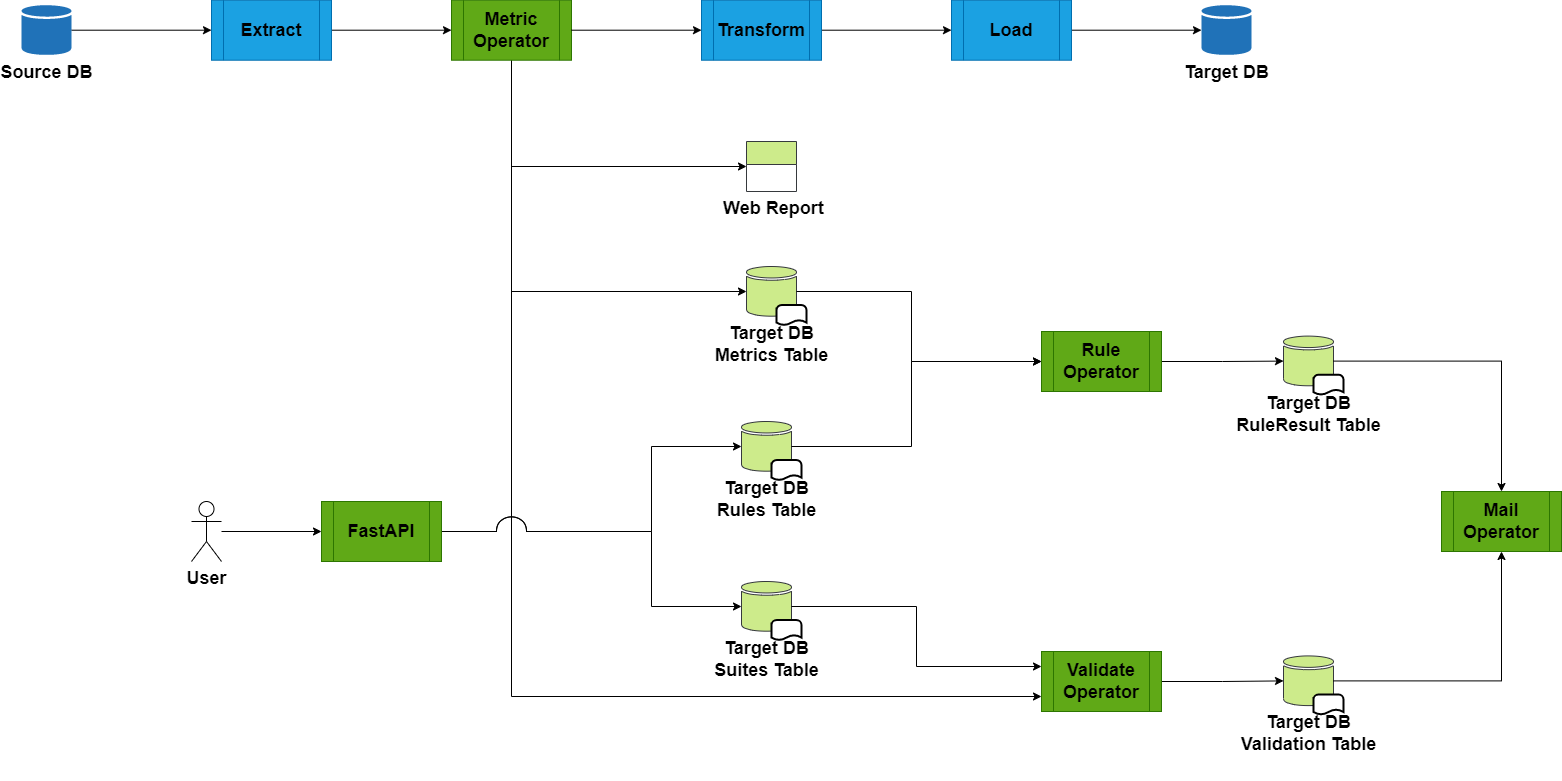
Rule Operator 及 Validate Operator 的目的,是讀取使用者所設定的檢驗物件,根據條件,查詢不同的內容:
較簡單的條件:
如果使用者設定的指標已經在
Metric Table中被滾算過了,可以直接進行比對,驗證速度極快。 (例如n_missing< 100)較複雜的條件:
如果使用者設定較為複雜的條件 (例如該欄位的值需要符合某個 Regular Expression ),此時需要對 Raw Data 進行滾算驗證,需要耗費較大量的時間。
運算框架
在進行資料品質滾算時,事先調查了幾個適合的框架,較為主流的資料品質檢驗工具有兩項:
AWS Deequ :
Deequ是 AWS 所開發的資料品質檢驗工具,底層是以Java建構,不過有釋出 Python 接口 (PydDeequ),由於使用時需要安裝不少相依套件,在銀行內會有安全性的考量,所以作罷。不過這還是一套相當主流的工具,也有支援 Spark 的 Integration。
Deequ 官方網站
Python Deequ 官方網站
Great Expectation:
Great Expectation則是Python-Based的開源套件,目的與Deequ相同,都是希望能做資料品質的驗證 (Unit tests for data)。相較於
Deequ來說,只需要透過Pypi安裝即可,相對友善。但缺點是文件較差,在版本更迭的過程中,有許多文件尚未補齊,主要是透過
Jupyter Notebook進行互動式設定。如果和我一樣,希望建立一個
Python SDK,底層封裝Great Expectation的話,對於其環境設定及運行方式,可能需要花一點時間摸索。Great Expectation 官方網站
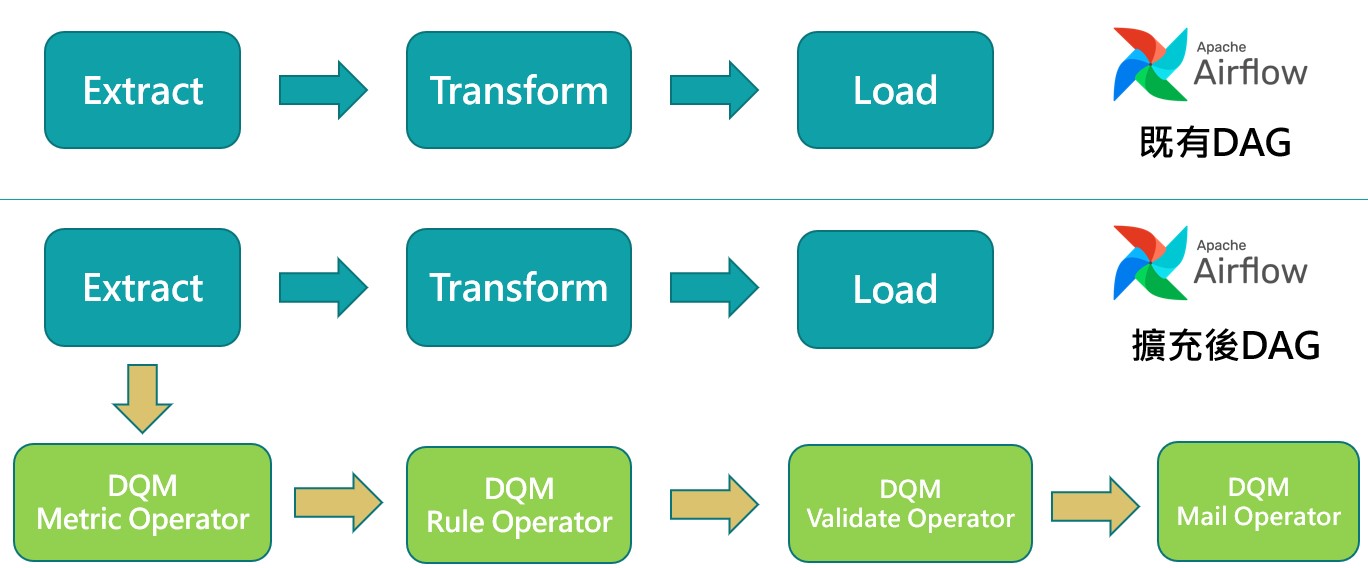
如何達到高相容性?
在本節開頭提到,建立此模組的第一個目標就是: 需與現有的ETL流程有極高的相容性,為了達到此目標,勢必與部門現有的 Airflow 流程做很好的結合。
開發這個模組時,是先以 Python SDK 作為開發目標,將 Great Expectations 等開源套件封裝成自行定義的規格。
接著,自行開發 Airflow 的Operator
(請參閱 - Creating a custom operator - Airflow Documentation)
這樣的好處是: 只要在原有的ETL DAG中進行擴充,即可達到檢驗資料品質的功能,不會影響到原有的 ETL流程 :
後話
最初是因為新工作在試用期結束前,需要自己完成一個專案,所以開始進行資料品質的研究,也根據現有流程設計一些模組。
在報告完後得到了不錯的回饋,也準備正式擴充到部門現有的400多個 ETL 上。
這篇文章算是在忙碌一個段落後,趁著聖誕假期,記憶還沒有模糊前,先將這陣子的知識點做個紀錄及分享。
整個模組的細節省略了不少,如果各位朋友對於這部分有興趣,歡迎來信或是透過各種方式連絡我,跟我一起深入交流~
祝大家聖誕快樂!